This is a part of the story of how I went from chipping away at archiving my movie collection one DVD at at time to running a bare-metal Kubernetes cluster capable of transcoding dozens a day.
At this point even though everything was running in Docker containers on a Kubernetes cluster, it wasn’t really all that resilient. When things went sideways it was up to me to restore state and get back on the happy path: identify which video had failed mid-transcode, move the files back into the watch directory, etc.
I briefly considered how to go about addressing this problem. Maybe I should store tasks in a job queue? 🤔 Instead I settled on what I think is a much more fun design: moving all the state into Kubernetes so that I don’t have to deal. Kubernetes had recently introduced the concept of jobs, executing a single task vs. an always running daemon, and I hoped to use that to my advantage.
I split up the original HandBrake container into separate components, each responsible for one task that could be handled by a Kubernetes job.
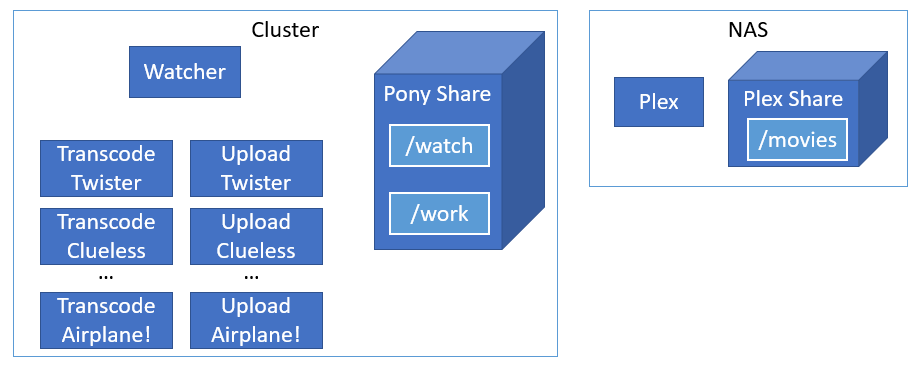
Watcher
This is a Go binary that … wait for it … watches a directory on a fileshare in the cluster for new videos. When a new video showed up it:
- Waits for the file size to stabilize because copying 30GB files can take time.
- Moves the file out of the watch directory and into a work directory.
- Creates a job to transcode the video.
- Creates another job to upload the finished video to Plex.
Each video has its own job, and that is a big part of how I managed to avoid dealing
with state myself. Kubernetes handles restarting the job if it failed, or I accidentally
unplugged a node while vacuuming. As a bonus, I no longer had to tail logs
to see what my cluster was up to! I could just run the Kubernetes dashboard, or kubectl get pods
and see a running list of active jobs.
Transcode Job
This is good old HandBrake again, only this time just the CLI, instead of that fat GUI image I was using earlier. It is incredibly simple: just call HandBrakeCLI and pass in the location of the video in the work directory.
Upload Job
This is a little more involved and is composed of two containers:
- jobchain - An init container that waits for the associated transcode job to complete successfully. This prevents the main container from starting until the transcode job is finished.
- uploader - Go binary that handles copying the finished video to Plex and refreshing the Plex library.
Manual state management averted! 🎉 I could schedule the two jobs when a new video was found and Kubernetes handled retrying the jobs until they worked. This was really amusing to see in action. More than once, I would deploy a change that broke all the transcode or upload jobs, Kubernetes faithfully kept retrying for days, and when I finally got around to fixing the bug all the jobs picked up the fix like magic! 🎩 ✨
 Pretty cool, eh?
Pretty cool, eh?
Remember when I boasted about how I was so awesome and did this entire project incrementally, never leaving it in a broken state and only tackling a single thing at a time? Heh. I’m sure you called bullshit when you first read that. In my defense, I did manage to do everything incrementally up until this point. But when I had finally outgrown that stock HandBrake container, and saw in front of me a greenfield of Go development… I got a little excited. 😉
Next: My Overkill